
Generative-inference models: Theory and empirical analysis (Part II)
The work presented in this blog is still in progress and summarizes my thesis’s chapters 5 and 6.
Background
In this blog we present a general formulation for generative-inference models from the perspective of representation learning. This formulation is obtained using the information theoretic concept of mutual information (MI). Shannon’s MI between the observable variables $x \in \mathcal{X}$ and latent variables $z \in \mathcal{Z}$ is defined as
$$\mathcal{I}_r(x,z) = \int_\mathcal{X} \int_\mathcal{Z} r(x,z) \log \frac{r(x,z)}{r(x)r(z)} ,dx ,dz $$
where $r(x,z)$ is the joint distribution of $x$ and $z$. The definition of MI depends on the choice of the joint distribution. In this case we have two definitions of MI, one for the joint distribution of the inference model $q(x,z)$ and one for the generative model $p(x,z)$. In what follows we will use the sub-indexes $q$ and $p$.
Representation learning in generative-inference models
To associate current generative-inference models with their representation learning capabilities we associate them with the MI of their model distributions.
We start by writting the MI of the inference model $q(x,z) = q(x|z)q(z)$ as follows
$$ \mathcal{I}_q(x,z) ~=~ -\mathcal{L}_q^{\text{model}} + \Delta \mathcal{I}_q^{\text{model}} ~~~~~~~~~~(1) $$
where the loss function of the model is given by
$$ \mathcal{L}_q^{\text{model}} = \mathbb{E}_{q(x,z)}[-\log p(x|z)] + \boldsymbol{{\mathcal{R}_q^{\text{model}}(x,z)}}, ~~~~~~~~~~(2) $$
and the mutual information gap of the generative-inference model loss function and the MI of the inference model is given by
$$ \Delta \mathcal{I}_q^{\text{model}} = \boldsymbol{{\mathcal{R}_q^{\text{model}}(x,z)}} + h_q(x) + \mathbb{E}_{q(z)}[D_{KL}(q(x|z) || p(x|z) )]. ~~~~~~~~~~(3) $$
The terms collected in $\mathcal{L}_q^{\text{model}}$ correspond to the loss function’s components of the generative-inference model. The loss function is composed by the likelihood and the term $\mathcal{R}_q^{\text{model}}$ which represents a set of restrictions (regularization) for the distributions of the model. This restriction vary depending on the model and is also part of the MI gap $\Delta \mathcal{I}_q^{\text{model}}$. Later we will recognize this restriction term in generative-inference models from the literature to show that their loss functions comply with this formulation.
The decomposition for the generative model distribution is symetrical. The term $\boldsymbol{{\mathcal{R}_r^{\text{model}} (x,z)}} \geq 0$ is a restriction over the distributions of the model and is included in both $\mathcal{L}_r^{\text{model}}$ and $\Delta \mathcal{I}_r^{\text{model}}$. When $\mathcal{L}_r^{\text{model}}$ is minimized the restriction is also minimized. A small value for the restriction is desirable as it reduces the gap. We want the gap to be low since helps the model to be closer to $\boldsymbol{\mathcal{I}_q(x,z)}$, which is a measure of correlation between to variables.
In conclusion, from a theoretical point of view we need two things:
- A high mutual information $\boldsymbol{\mathcal{I}_q(x,z) }$, because the mutual information represent a measure of correlation.
- A low gap $\boldsymbol{ \Delta \mathcal{I}_q^{\text{model}}}$, because $\boldsymbol{ -\mathcal{L}_q^{\text{model}} }$ is a bound of $\boldsymbol{\mathcal{I}_q(x,z) }$.
In the following we show a diagram of the decomposition of the mutual information of the inference model.
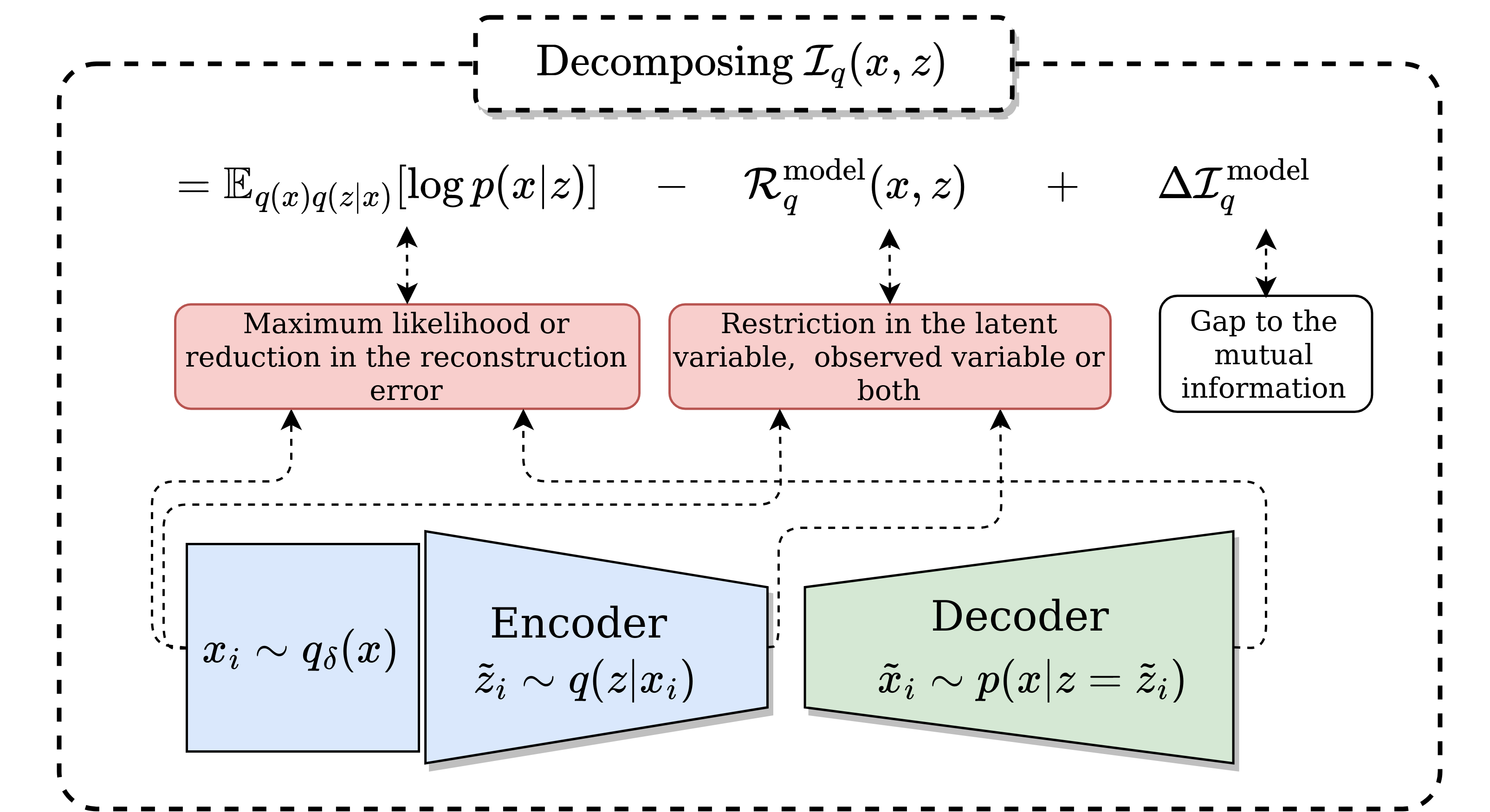
Associating generative-inference models with mutual information
In the literature $\boldsymbol{{\mathcal{R}_r^{\text{model}} (x,z)}}$ has been utilized to match some of the distributions of the inference model and/or generative model in addition to the decoder likelihood $\mathbb{E}_{q(x,z)}[\log p(x|z)]$ or encoder likelihood $\mathbb{E}_{p(x,z)}[\log q(z|x)]$. The only thing that change between models is the restriction used. In the following we showed what generative-inference models fit with this decomposition.
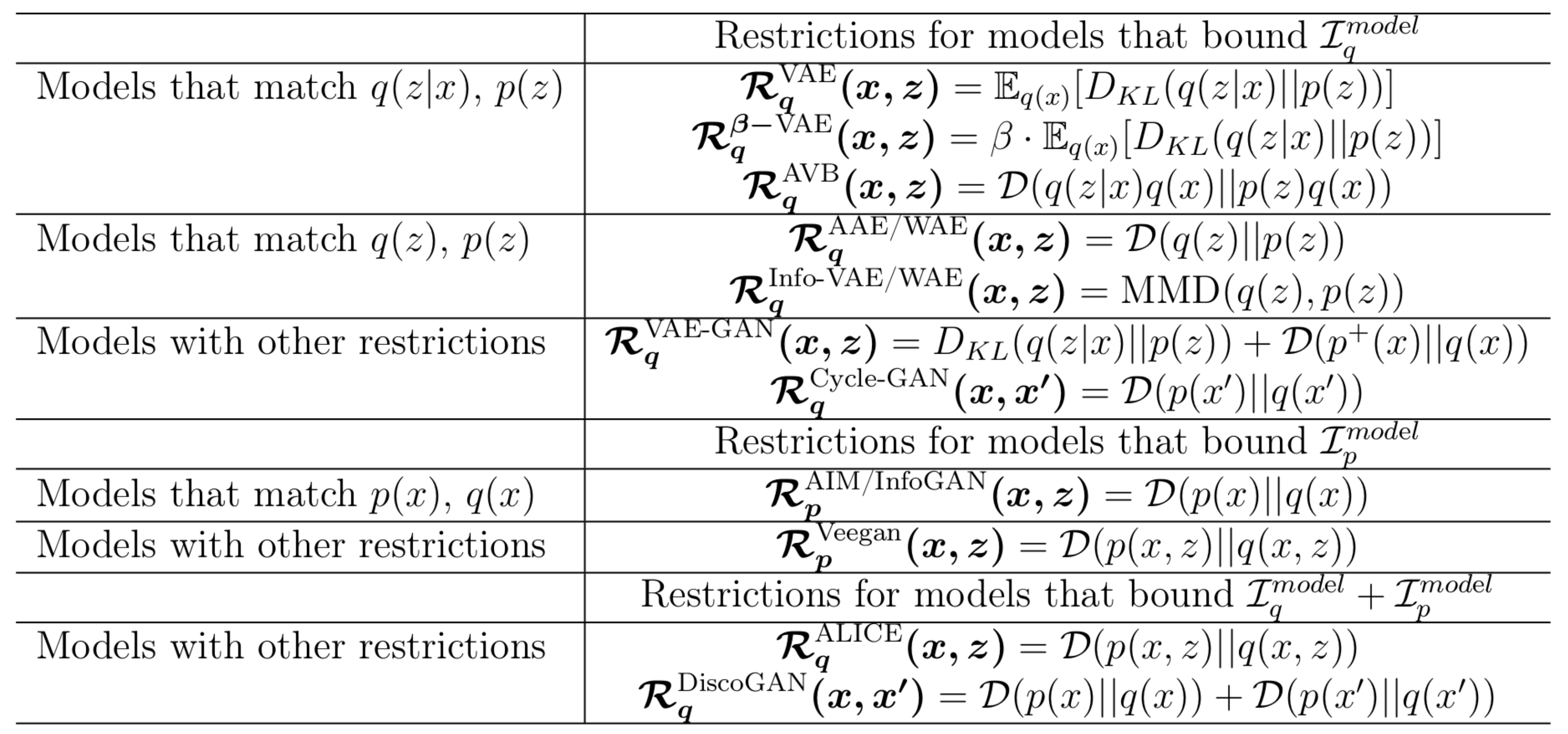 Restrictions of different generative-inference models. The $\mathcal{D}$ can be replaced for any adversarial training. The variable $x' \in \mathcal{X}'$ refers to data in a high dimensional space. We have a lot models!: VAE, [$\beta$-VAE], AVB, AAE, WAE, Info-VAE, VAE-GAN, AIM, Info-GAN, VEEGAN. ALICE, CycleGAN.
Restrictions of different generative-inference models. The $\mathcal{D}$ can be replaced for any adversarial training. The variable $x' \in \mathcal{X}'$ refers to data in a high dimensional space. We have a lot models!: VAE, [$\beta$-VAE], AVB, AAE, WAE, Info-VAE, VAE-GAN, AIM, Info-GAN, VEEGAN. ALICE, CycleGAN.
What models are better for representation learning?
We have associated generative-inference model with the mutual information of the model’s distribution. But what loss function of the models are useful for representation learning?.
To answer this let me write the mutual information in slightly different way. In the following, we will analyze representation learning capabilites for models that optimize a bound of the inference model mutual information (the analysis for the MI generative model is symetrical).
We can write the mutual information of the inference model as: $$ \mathcal{I}_q(x,z) ~=~ \mathbb{E}_{q(x)}[ D_{KL}(q(z|x)||p(z))] - D_{KL}(q(z)||p(z)), ~~~~~~~~~~(4) $$
Taking in consideration Eq. (4) we can note that for representation learning minimizing the restricction $\boldsymbol{{\mathcal{R}_q^{\text{model}}(x,z)} = D_{KL}(q(z)||p(z))}$ is better than minimizing $\boldsymbol{{\mathcal{R}_q^{\text{model}}(x,z)} = D_{KL}(q(z|x)||p(z))}$.
- Minimizing $\boldsymbol{{\mathcal{R}_q^{\text{model}}(x,z)} = D_{KL}(q(z)||p(z))}$ like WAE maximizes the inference model MI by reducing the right hand side in Eq. (4), moreover it minimizes the MI gap in Eq. (3).
- Minimizing $\boldsymbol{{\mathcal{R}_q^{\text{model}}(x,z)} = D_{KL}(q(z|x)||p(z))}$ like VAE minimize the inference model MI by reducing the left hand side in Eq. (4). In consequence reducing MI gap in Eq. (3) will reduce the MI of the inference model.
The analysis is symetrical for models that bound generative model.
Trade off between representation learning and generation
It seems that VAE are worst than WAE models. But we note that exists a trafe-off between generation and representation which is associated to the prior that we used. We will consider the common prior $p(z)=\mathcal{N}(0, 1)$. We note that models that compress all the information in the prior have better generative learning capabilities but worst representation learning capabilities, and viceversa.
This occurs because if all input information is compressed in the latent space, in some part of the latent space different classes will be close.
Under this thinking, GANs, which have better generative capabilities than VAEs, should have worst representation learning capabilities. VAEs should have better generative capabilities than WAEs since the entropy term $h(z|x)$ helps them to cover information of the input in the prior. A diagram of this thinking in the following:
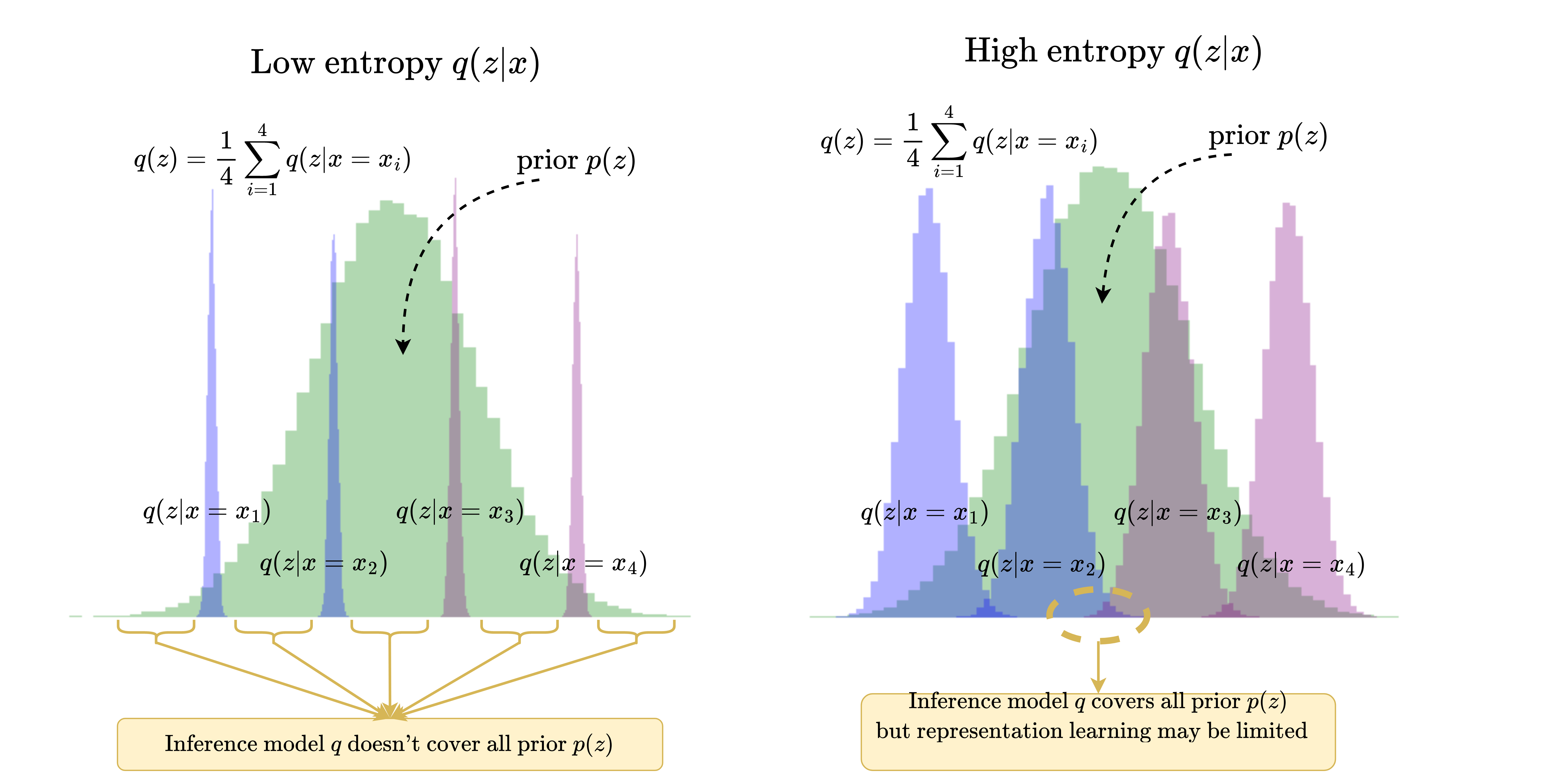
We observed this behaviour empirically with MNIST (and many more experiments in my thesis, which the explanation are also more developed) where we estimated $\tilde{\mathcal{I}}_q(x,z) = h(z) - h(z|x)$ by approximating $q(z)$ as Gaussian distribution:
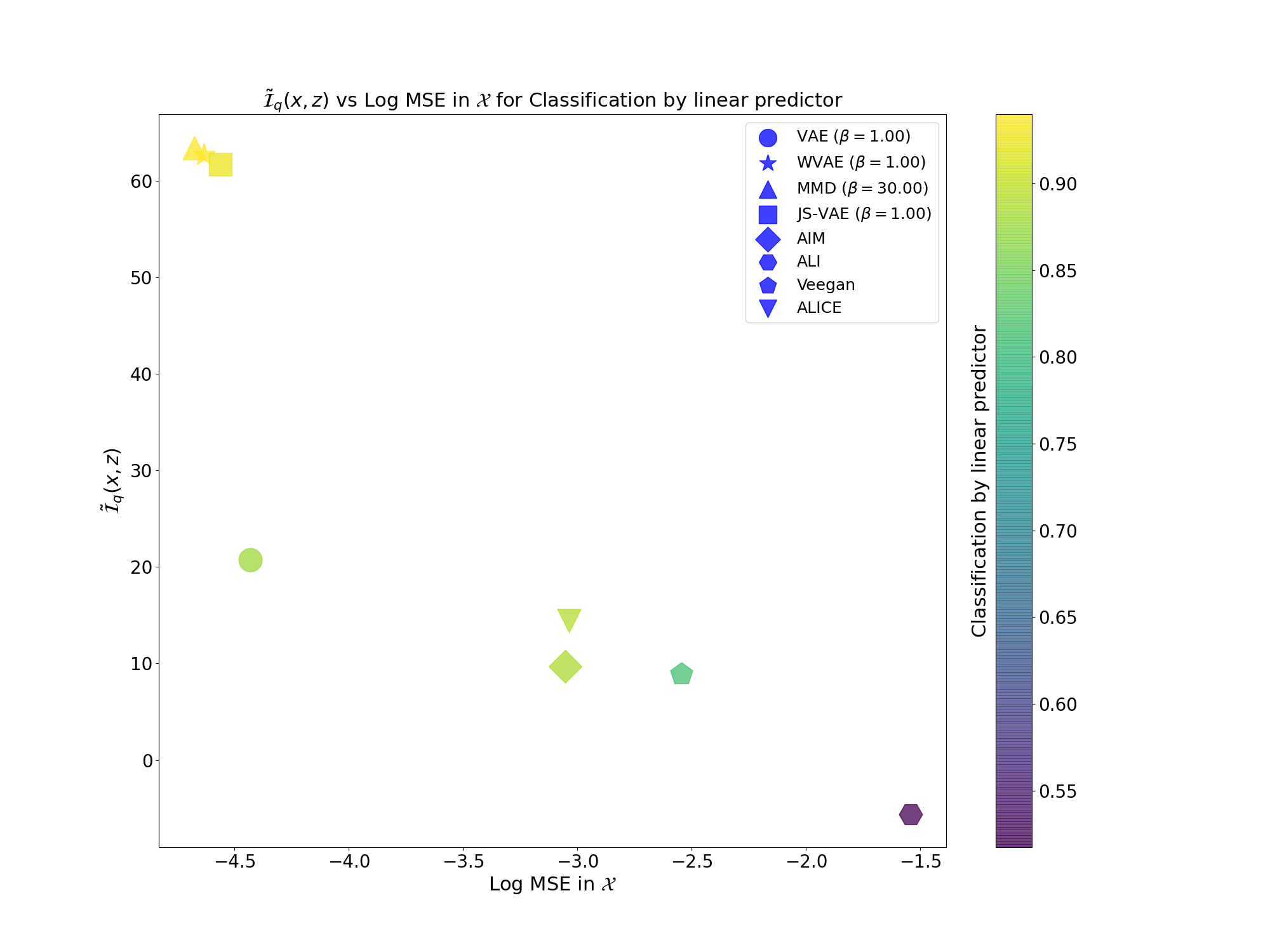
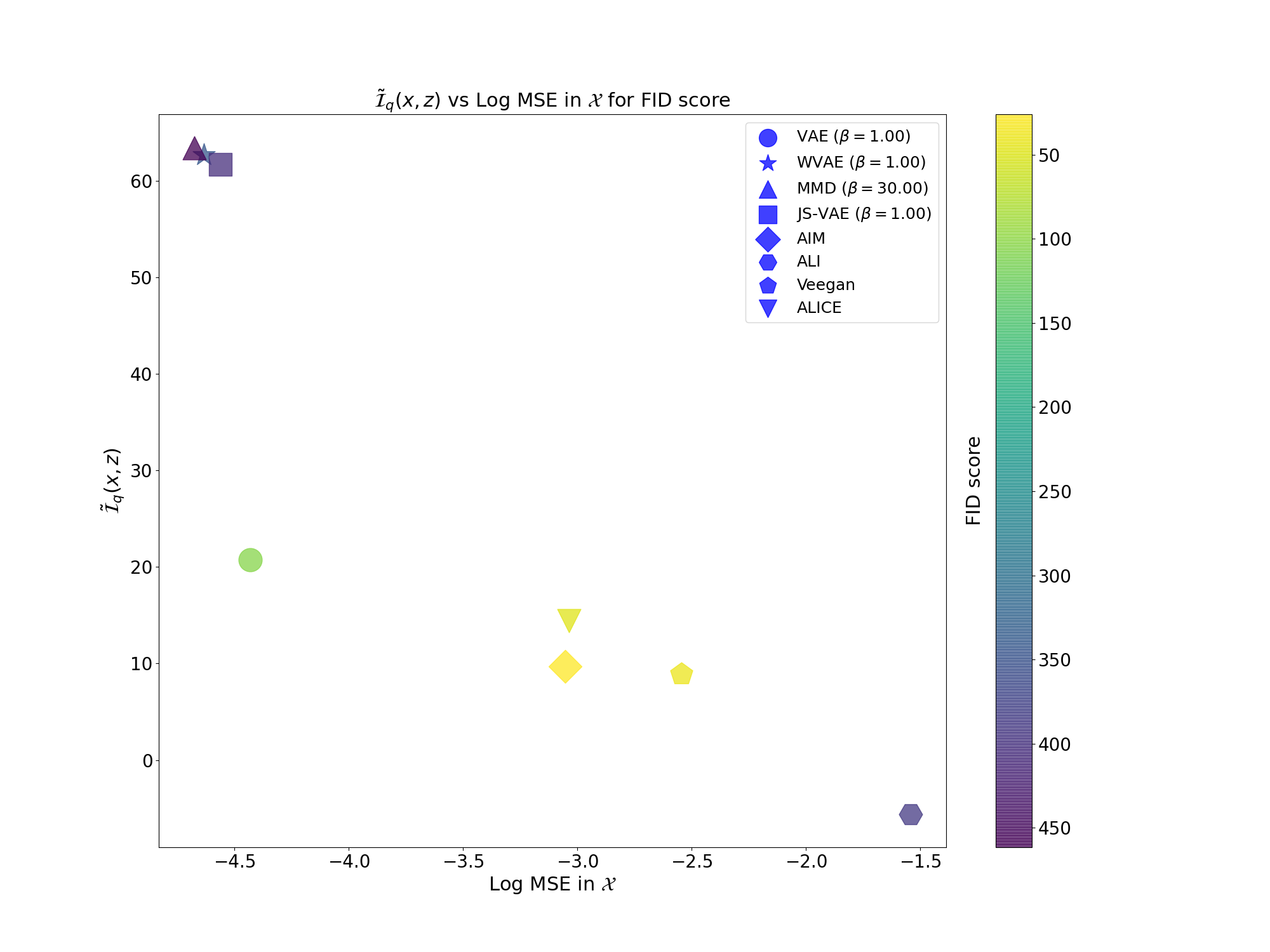
WVAE and JS-VAE are models that I proposed in my thesis (All methodology is also explained here).
From the plots above we can clearly see that models that perform better at generation (FID score) have worst representation learning capabilities (Linear probing on latent space). Also, better models for representation (Linear probing on latent space) have worst peformance in generation (FID score).