
Working at ALeRCE
Currently, I am working part-time in ALeRCE (Automatic Learning for the Rapid Classification of Events) as machine learning engineer. ALeRCE is a Chilean-led broker that process alert streams of astronomical data. The amount of astronomical data is huge and autonomous mechanisms are necessary to detect new interesting astronoimcal objects (note, we can not put a bunch of astronomers to look images of the sky). Being part of ALeRCE is my closest attempt to engineering, and it has been an entertaining journey. I have had a lot of fun of being part of the practical process to put ML models in production to make scientific discoveries. In the following I will explain some of the work that I do in ALeRCE.
I can summarize my work in:
- Training sets creation.
- Putting ML models in production.
- Miscellaneous.
- Training interesting ML models :o.
I will talk about the first two, since I can not disclose information about the fourth one and the third one can be various things (usually lifting some service using kubernetes).
Creating training sets
To train ML models we need to prepare training sets i.e. pairs of data $(x, y)$ (for the supervised learning). The $x$ is obtained through observatories or surveys that collect data from them, the labeled information is collected in a different way. In astronomy we only can obtain labels if someone (astronomers) have already classified some astronomical objects. This labeled information is saved as catalogs and we can have many catalogs even from the same survey.
To create big training sets, we need to extract the labeled information from various catalogs and combine them. In the following image I show a diagram of how we labeled data from some data source,
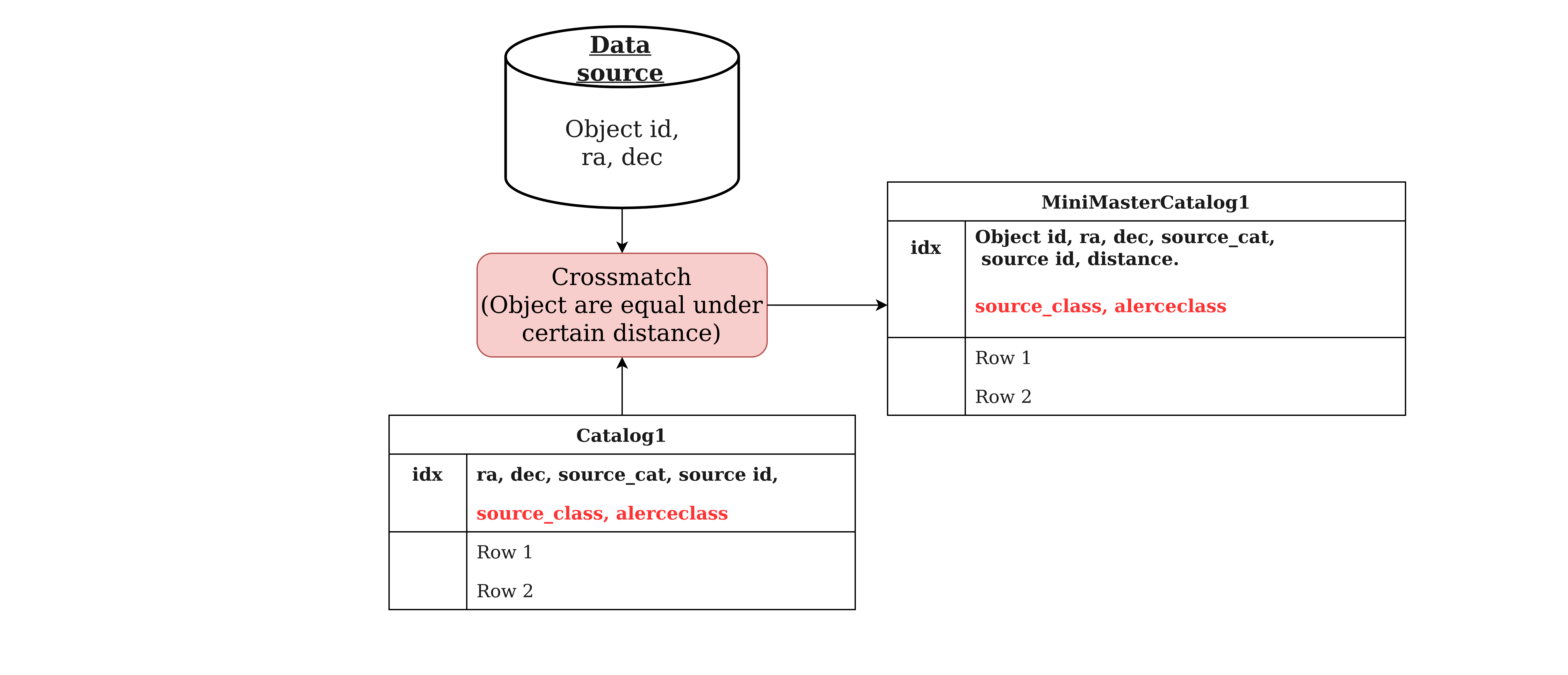
The procedure basically consists in taking the data source and crossmatch it with some catalog. We know if an object (from the data source) have certain label if it is really close in distance with some object of the catalog i.e. these objects are the same.
Finally we can combine the results of many crossmatches creating our training sets.
Putting models in production
One of the other task that I do in ALeRCE is putting models into production. As you can see in ALeRCE, this pipeline consists in basically:
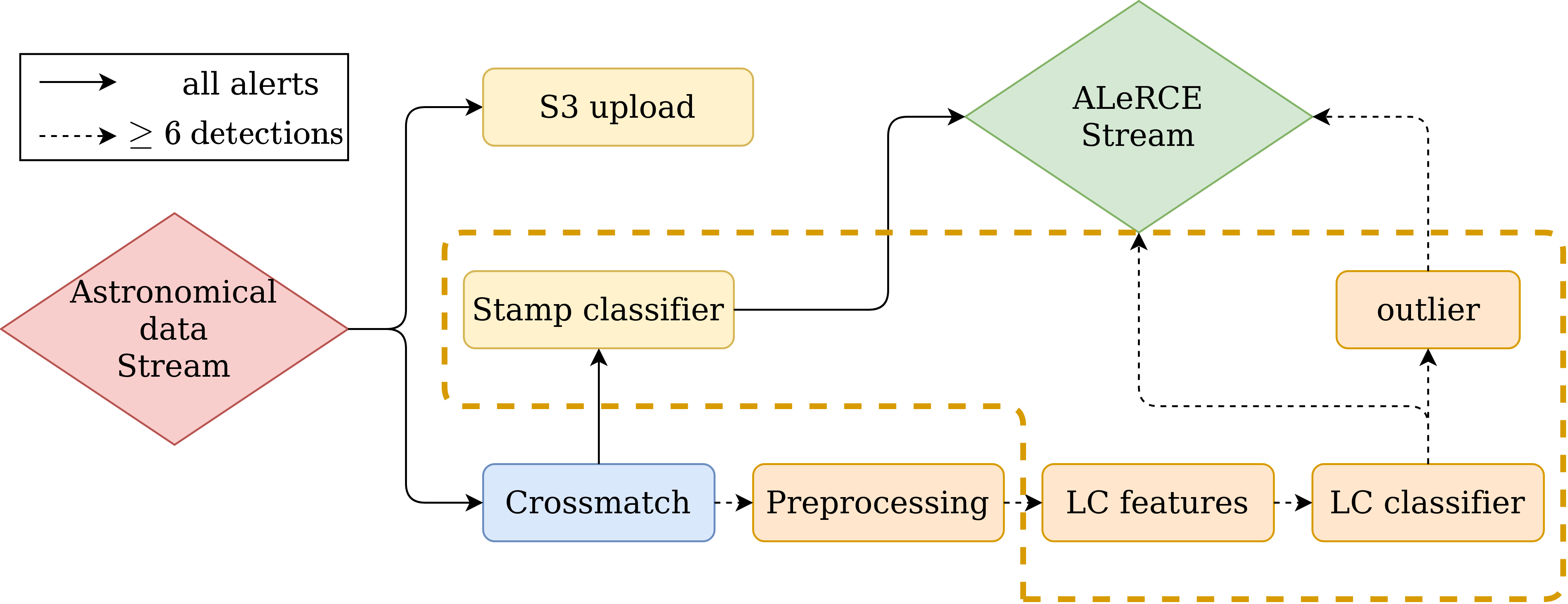
We communicate all of these steps (boxes) using Kafka. I am usually involved in the steps that are inside of the orange dotted lines. To put some step in production, we need to use Kafka to consume from a topic and writting in databases (MongoDB and postgresSQL) to save our predictions. Finally we use docker with kubernetes to put our machine learning models into the pipeline.