
LGAd: Lightcurve generative model for anomaly detection
LGAd is a variational generative model for variable length and irregularly sampled times series. As a variational model the loss function is obtained by maximizing a bound from the likelihood $\boldsymbol{\mathbb{E}_{q(x)}[\log p(x)]}$.
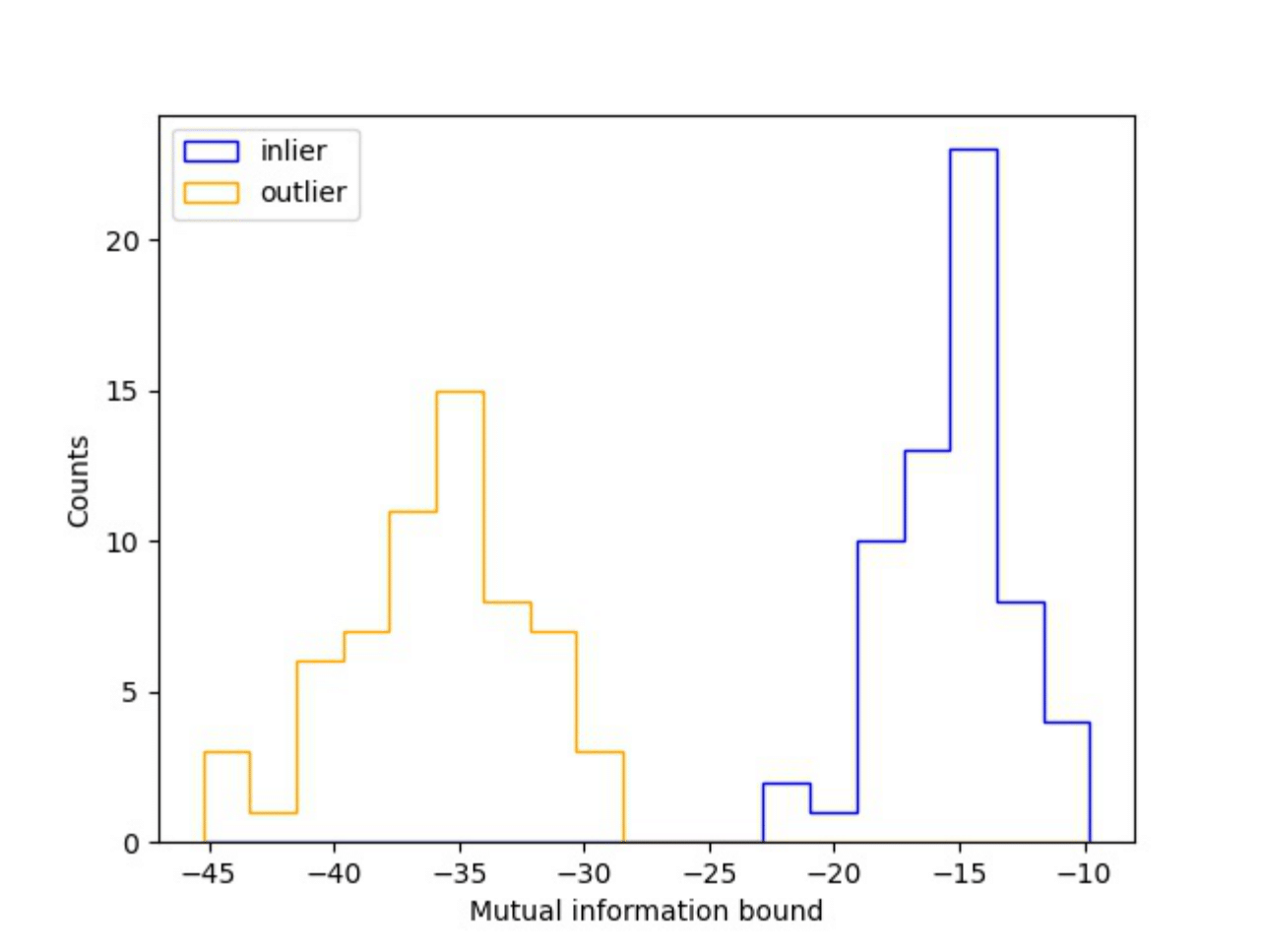
For anomaly detection we used $\boldsymbol{\hat{\mathcal{I}}(z,y|\cdot)}$, a bound of the mutual information (MI) between the continuous latent variables $\boldsymbol{z}$ and the categorical latent variables $\boldsymbol{y}$. From some input $\boldsymbol{x_i}$, a low MI bound means that our codification $\boldsymbol{z_i}$ is not correlated with our categorical variables $\boldsymbol{y}$ (Anomalous, or outlier). On the contrary, a high MI bound means that our codification $\boldsymbol{z_i}$ is correlated with our categorical variables $\boldsymbol{y}$ (inlier).
In the following, we show how it looks the MI bound using astronomical data. For more details take a look to my Master thesis (in my thesis this model is called TS-VaDE).
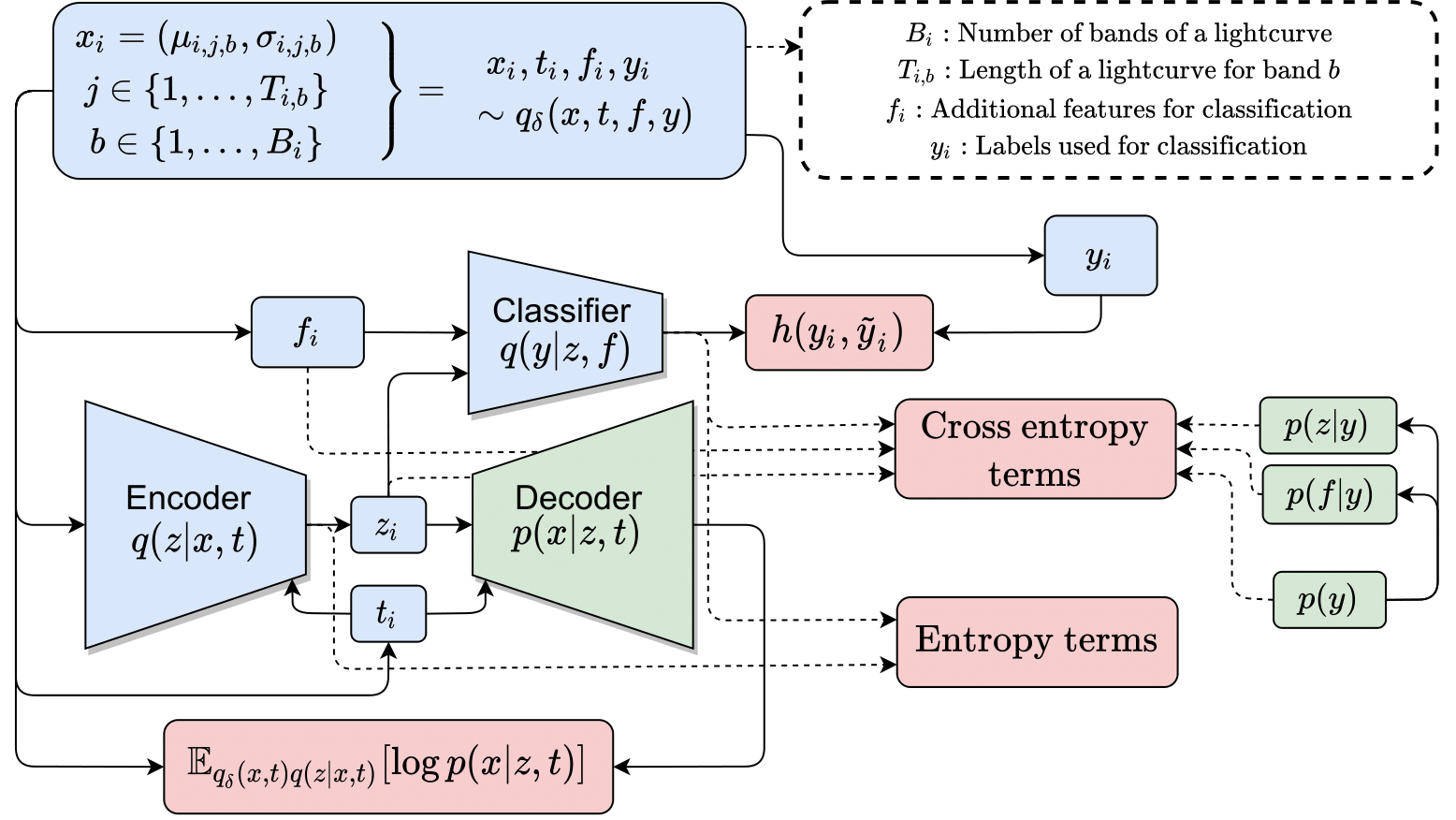
Model
The graphical model of LGAd is:
- $p(x,z,y,f|t) = p(x|z,t)p(z|y)p(f|y)p(y)$
- $q(x,z,y,f,t) = q(x,f,t)q(z|x,t)q(y|z,f)$,
where $\boldsymbol{x \in \mathcal{X}}$ is the observed variable, $\boldsymbol{t \in T}$ are the times associated to the observed variable $\boldsymbol{x}$, $\boldsymbol{z \in \mathcal{Z}}$ is the latent variable, $\boldsymbol{y \in \mathcal{Y}}$ is the categorical latent variable and $\boldsymbol{f \in \mathcal{F}}$ is a metadata variable that helps in classification but is not worthy to compress in a latent variable $\boldsymbol{z}$.
In practice we found that using labeled data improve the outlier detection performance so we include a cross-entropy term between the logits and the true labels. The loss function of LGAd can be summarized as follow:
$$ \mathcal{L}^{\text{LGAd-supervised}} = \mathcal{L}^{\text{LGAd-unsupervised}} + h(y, \tilde{y}), $$
where $h(y, \tilde{y})$ is a common cross-entropy of a classifier and the true labels, and $\mathcal{L}^{\text{LGAd-unsupervised}}$ is the unsupervised part of the model, obtained using VAE derivation:
$$ \mathbb{E}_{q(x,t)}[\log p(x|t)] \geq \mathbb{E}_{q(x,z,y,f,t)} \left[\log \frac{p(x,z,y,f|t)}{q(x,z,y,f,t)} \right] $$
$$ \equiv \mathbb{E}_{q(x,t)q(z|x,t)}[[\log p(x|z,t)] + \mathbb{E}_{q(y|z,f)}[\log p(z|y)] $$ $$ ~ + \mathbb{E}_{q(f)q(y|z,f)}[\log p(f|y)]] + \mathbb{E}_{q(y)}[\log p(y)] $$ $$ ~ + h(y|z) + h(z|x) \equiv -\mathcal{L}^{\text{LGAd-unsupervised}}, $$
where $\mathbb{E}_{q(x,t)q(z|x,t)}[[\log p(x|z,t)]$ is the likelihood of the decoder (reconstruction error), $\mathbb{E}_{q(y|z,f)}[\log p(z|y)]$, $\mathbb{E}_{q(f)q(y|z,f)}[\log p(f|y)]]$, $\mathbb{E}_{q(y)}[\log p(y)]$ are likelihoods of the encoded latent variables over the priors of the generative model. Finally the last terms are entropy terms that are maximized in order to reach non trivial solutions. A diagram of all training procedure is shown as follows:
For anomaly detection we proposed a new anomaly score called IAS (Information anomaly score). IAS consists in measuring the correlation between the latent variables $\boldsymbol{z}$ and $\boldsymbol{y}$ using an estimate of true mutal information $\boldsymbol{\mathcal{I}}(z,y|\cdot)$. This mutual information is approximated as follows: $$ \mathcal{I}(z,y|x,f) = \mathbb{E}_{q(z,y|x,f)}[\log p(z|y)] + h(z|x) + \mathbb{E}_{q(x,y)}[D_{KL}(q(z|x,y) || p(z|y) )] $$ $$ \geq \mathbb{E}_{q(z,y|x,f)}[\log p(z|y)] + h(z|x) \equiv \text{IAS}(x),~~~~~~~ $$
More results are in my Master thesis, but we are working to publish a paper with this model and anomaly score.